Managing healthcare data from diverse sources is challenging. Before any insights can be gained, the data must be processed and normalized. In this webinar, we discussed how Zephyr AI makes sense out of massive amounts of data using Rhapsody Semantic to ensure readiness for Machine Learning (ML) modeling.
You can watch the on-demand webinar, How Zephyr AI creates precision data models at scale with Rhapsody Semantic. We’ve also provided a summary of the Q&A from the webinar below.
Webinar participants included:
- Shelley Wehmeyer, senior director, product and partner marketing, Rhapsody
- Camilla Frejlev Bæk, product owner, terminology, Rhapsody
- Amy Sheide, VP, data platform and partnerships, Zephyr AI
Skip to:
- What problems is Zephyr AI solving?
- Clinical data can be messy. How does Zephyr AI approach this?
- What practical solutions does Zephyr AI have in place for healthcare data normalization?
- How does Zephyr AI amplify certain data elements and turn down the noise, for example when using LOINC codes?
- Diagram: From data ingestion to AI modeling in less than 30 days
- Auto-mapping algorithms and custom content with Rhapsody Semantic
- How ZephyrAI engineers use Rhapsody Semantic APIs
- How Rhapsody Semantic aggregates data from different systems
- What a Rhapsody Semantic deployment looks like
Shelley Wehmeyer: Amy, can you give us a brief introduction to what Zephyr is building and what problems you’re solving on behalf of customers?
Amy Sheide: We focus on a core technology platform that ingests multimodal data that can provide insights. When we talk about the full spectrum of precision medicine from prevention to treatment, we talk about stratifying patients to get them the right care.
This means the right medications, the right treatment pathways, and preventing specific adverse outcomes from occurring, like chronic condition development in type two diabetes, or adverse events in cancer populations.
Specifically, what we look at is bringing together disparate data sources and transforming those insights into action so that we can change the quality of life of patients and look for a better future.
SW: When that data lands, it’s often very disorganized. Clinical data can be messy. EHR records are not standardized. How do you approach that?
AS: Our biggest challenges are bringing the data in and making that data ready for machine learning and AI — and making that at scale, meaning the transformations, iterations, and the implicit relationships in the data. All of this is critical to get us on the path to producing predictions that are not only accurate, but based on real data that pertains to real patients.
Camilla Frejlev Bæk: It could be that two of the EHRs are using ICD 10, but maybe different versions. It’s important we keep both the historic overview of the code systems as well as the versions, making sure that we have the accurate code. So, even though it’s the same code, it might be from a different version of the same code system. It’s complex.

SW: Preprocessing clinical data is labor-intensive. Cleansing data before training predictive models takes up 80% of a data scientist’s time. Data normalization can take up nearly a third of the time. We need pragmatic, practical solutions in place.
Amy, when you were looking at the architecture you would need for your team to succeed, what were the most important considerations?
AS: The value of our engineering team and our data science team, who is the best in class, is to empower them and enable them with data that can produce the outcomes and predictions that we need.
What that means for Zephyr and our data team is to be able to produce a very rich feature set. This means that we have normalized codes, we have grouped the codes into meaningful subsets and value sets, and we’ve exported all of the implicit data relationships that are important to the models.
By the time we have curated a feature set from the raw data, it’s essentially at a place where the data scientists don’t have to spend their time doing any more quality checks or cleansing tracks. It’s ready for them to build the algorithms as soon as it lands from the processing pipeline.
The other part of it is scalability. When data lands, it’s incredibly important for us to process large amounts of data, a large variety of data, and changes in the data over time. We’re a small team and we need to be able to move quickly and efficiently, and we need to be able to iterate. That means having a tool and a workflow that allows us to build content and manage all of the mundane aspects of terminology management.
Imagine the large amounts of data that we have to process, including millions and millions of rows of data. We have to be able to deploy our APIs at scale. So, whether we are processing this data with Spark, or operationalizing the transformations within our pipeline, the whole point is for engineering to essentially be able to use the set of APIs and not have to truly understand the underlying constructs or rules of the data, but rather focus on what they do best, and just build the ETL processing pipelines.
SW: You need the visibility and flexibility to deal with data in context and to figure out what to amplify and when to turn down the noise — for example, with LOINC codes.
AS: One of my favorite examples: If you take one simple clinical measurement, like a lab result, that lab result can have multiple texts, representations, or different LOINC codes. We see a mixed bag of this in the real world where you can have synonyms for lab tests. You can have different representations of different strings, but they all mean the same thing clinically.
We have an example for our eGFR glomerular filtration rate lab with more than 2 million lab results from one source and about 60 different text representations that we had to encode to LOINC and map to four different LOINC codes. Then, within the data of the text representations, there is also data encoded with LOINCs. So ultimately, 10 different LOINC codes cover about 5.4 million rows of data that essentially represent the same clinical concept.
We use the flow of data, the semantic APIs, to bring up the signal from all of those different representations to clinically represent and recognize that as one single lab measurement. Balancing the signal-to-noise ratio, in whatever your task is, whether it’s machine learning, analytics, or business intelligence, you always need to measure and be able to look at the data in that complete view and understand what is clinically going on.
SW: Here’s the diagram we built based on your use case and the primary ways you’re using Semantic today.
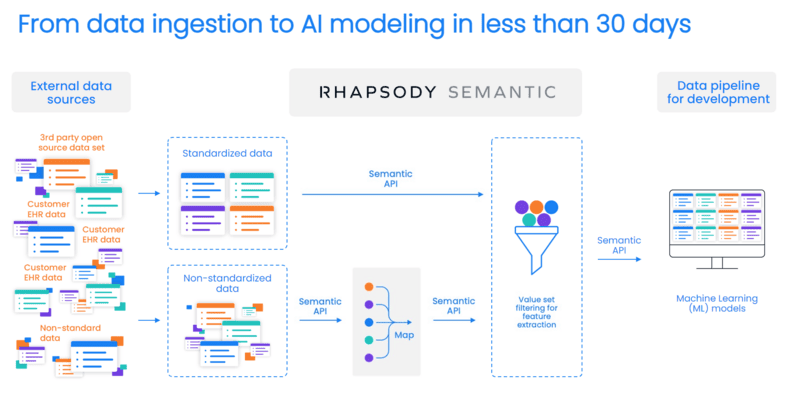
SW: On the left-hand side, we see those external data sources that you’re plugging into to get the quantity of data that you need to build the models. You run it through the semantic APIs to be mapped and then can filter it to turn down the noise and amplify what you need before sending it over to your development teams for machine learning and modeling.
AS: I think this diagram is a really great showcase of how it all comes together. The thing that doesn’t come out in the diagram that we find helpful at Zephyr AI is the workflow and the tooling within Rhapsody Semantic for us to essentially curate these mappings.
A lot of organizations will do this with a homegrown solution — whether they’re handing around spreadsheets or building tools in Microsoft Access, or ad hoc analysis. Because we’re a distributed team, we have to have tooling that allows us to access the content and the metadata and review our content and change seamlessly between team members.
SW: What’s coming in the roadmap about what we can do to engage auto-mapping algorithms and supply our customers with the content they need to map for their use cases?
AS: The advanced algorithm configuration for the mapping is incredibly valuable to us because it allows the data team to leverage their knowledge about the relationships in the different terminologies. The configuration of the algorithm narrows down the mapping space so it’s not so overwhelming when you’re trying to find matches.
CFB: Out of the box, we provide a lot of standards and mappings, but the more you put in there, the better it gets. It’s to make the algorithm smart from the beginning and leverage the information that you have. We need to make sure that we also leverage all the information and its uniqueness to make sure we create high-quality mappings and reduce the amount of time.
SW: Let’s talk a little bit more about the APIs being used and how they’re used. What value does that bring upstream and downstream?
AS: The flexibility in the APIs has been very important to us. There’s quite a variety of input into the APIs in terms of API parameters. But the suite of APIs is flexible enough to support what transformations we need.
Our engineers can essentially implement the APIs as a black box. While the data team manages the content in the background, the APIs do the work of the transformation. This lets the engineers work on operationalizing the APIs.
SW: How does Rhapsody aggregate data from different systems?
CFB: In terms of Semantic, we provide standard code systems out of the box. We make sure that all these files are distributed, so everyone benefits from the latest content. But if there are other formats, we can put the integration engine on top to receive the data and make sure we have a flow into Semantic. We can make that integration, with integration engines receiving data from other structures.
SW: What is the deployment of Rhapsody Semantic like?
CFB: We have different options. You can do it in the cloud or on-prem. We provide a containerized image of the product.
AS: We deploy the container version of the health term. We operationalize and scale both parallel and horizontally with a Spark cluster. And then we orchestrate our Spark jobs using Dagster.
SW: Thank you all. You can access the case study we wrote with Zephyr about their success and use cases within Rhapsody Semantic, titled “From data ingestion to production in less than 30 days: How Zephyr AI uses Rhapsody Semantic to create precise AI models at scale.”


