Recently Jeff Duncan, Ph.D., State Registrar and Director of the Division for Vital Records and Health Statistics for the Michigan Department of Health and Human Services, sat down with Rhapsody health solutions experts to discuss the challenges his department has faced in sharing vital statistics data. He also shared how he’s stewarding recent Data Modernization funding by taking advantage of built-in FHIR capabilities in the Rhapsody Integration Engine to share death records with the National Center for Health Statistics.
You can watch the on-demand webinar How Michigan Department of Health and Human Services boosts modern data exchange with Rhapsody. We’ve also provided a summary of the Q&A from the webinar below, edited for brevity and clarity.
Webinar participants included:
- Jeff Duncan, state registrar and director, division of Vital Records and Statistics, Michigan Department of Health and Human Services
- Alyson Crabtree, client support manager II, Rhapsody
- Drew Ivan, chief product and strategy officer, Rhapsody
Skip to:
- The history of tracking vital records
- Meaningful Use
- Funding for National Vital Statistics System
- Advantages of FHIR
- How Michigan Department of Health and Human Services uses Rhapsody Integration Engine
- FHIR implementation
- What were some challenges you faced as an early adopter of FHIR?
- How are you solving patient matching problems?
- Are there legal issues with sharing vital records with other programs?
- Detecting data quality issues
- FHIR training
Drew Ivan: Any discussion of modern data exchange starts in the past. Vital records have long played a key role as one of the first data sources for public health.
Almost 500 years ago, the English government started tracking mortality by cause of death, compiling “bills of mortality” that were distributed through paid subscriptions. In the 19th century, none other than Florence Nightingale suggested the categorization of hospitalizations in order to facilitate descriptive statistics and analysis. This led to the International Classification of Diseases (ICD) codes.
When we look at modern process flows for registering births and deaths, the complexity of steps and participants involved is clear: These vital records both generate administrative overhead and a great source of data for public health.
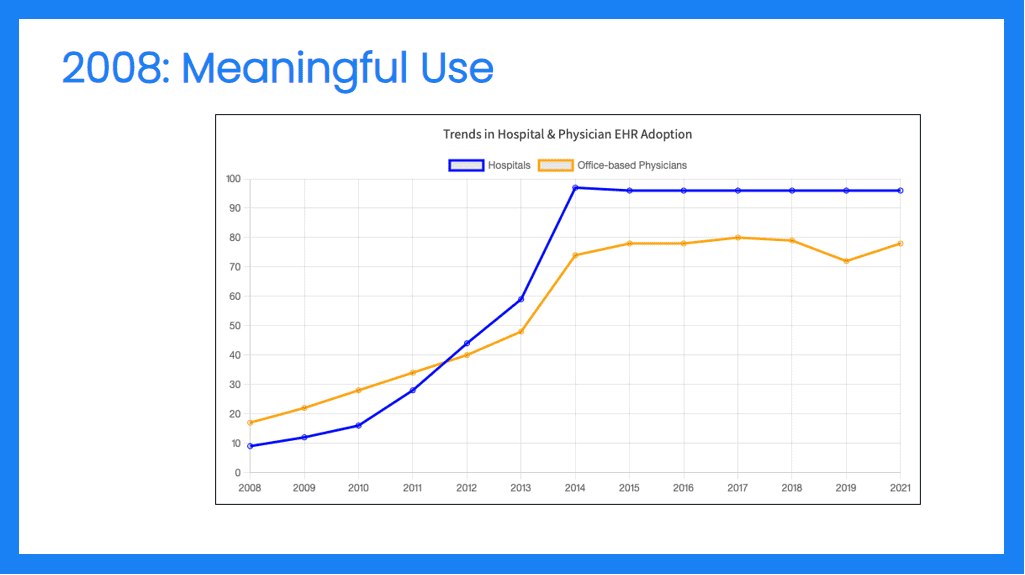
DI: 2008’s American Recovery and Reinvestment Act triggered Meaningful Use rules, which drive providers toward storing records electronically.
Currently, we’re at 90% adoption, with a good fundamental electronic infrastructure for recording healthcare data. However, there wasn’t a similar investment on the public health side to receive all of that electronic data, especially that generated during the pandemic.
Alyson Crabtree: When I worked in public health and watched Electronic Laboratory Reporting (ELR) data flow, I saw data quality and automation gaps, inconsistent coding, patient self-misrepresentation, and inadequate identifiers to deterministically merge lab results into case management systems. It was hard to answer questions from decision-makers and the public.
Jeff Duncan: While Meaningful Use brought technical infrastructure, at the start of the pandemic Vital Records wasn’t positioned to code deaths quickly and accurately. We sent cause of death literals, or what physicians write on death certificates, to the National Center for Health Statistics (NCHS), get codes back, and physicians write free texts. As just one example, they wrote COVID-19 in hundreds of different ways, even misspelling it.
To provide accurate statistics, data must be coded. A large proportion of Michigan residents were dying early in the pandemic, and decision-makers wanted to know where and who deaths were happening to. Were the deceased old? Young? What’s their racial background? Did they have comorbidities?
It took weeks to get codes back from NCHS because of this cumbersome, high overhead batch process. All the manual work was too slow in a pandemic situation that was moving very quickly.
AC: We’re looking today at sizable funding to modernize the vital statistics system. What are you hoping to take from this project?
JD: We tried for years to develop data exchange standards for coding, but we never really got anywhere until COVID. The pandemic served as the stimulus for federal funding to bring vital records into the interoperable age with the CARES Act.
The National Vital Statistics System got $77 million to develop Fast Healthcare Interoperability Resources (FHIR) for coding ICD-10 causes of death. So instead of batch processes and manual file uploads and downloads, a FHIR-based API returns a code in near real-time for a death certificate.
When that funding was released, states were faced with not only trying to implement a record-based standard, but a FHIR standard, which most people were not familiar with. FHIR was seeing some use but not a lot of public health adoption.
AC: You have done a lot of legwork for the CCDA; how does FHIR differ from other solutions and what are the advantages?
JD: FHIR’s API approach readily adapts to the workflow that we have of a per record, a record, and a response through an API and the information model in FHIR based on resources. It’s less rigid as the RIM was in the CCDA world, and much more flexible for use cases like sending deaths to the NCHS as opposed to sending deaths to a neighboring state for their residents. The information needs are slightly different, and FHIR can adapt implementation guides to meet those needs without developing entirely new standards.
AC: Given increased funding, what should your tech stack look like?
JD: Every state now has a web-based electronic death system where funeral directors can log into medical examiners. You can go to a vendor and have a FHIR API built, or you can build what’s called a FHIR facade, or you can use something that you already have.
But given implementations, hosting, testing, vendors, state IT agencies, and work processes, money is spent fast. We were looking at a way to do it quickly and inexpensively and Michigan Department of Health had Rhapsody Integration Engine.
Meaningful Use spurred the adoption of electronic case reporting of syndromic surveillance of many other public health use cases, which led health departments to invest in Rhapsody as an integration engine as a means of getting these HL7 version two and version three CCDA messages and bringing them into legacy systems.
Whatever that standard is coming in, you can develop flow paths, transform that data, and put it into the systems where it needs to go. And you can put it in lots of different systems, which is what happens in public health. We had Rhapsody, but no one had used FHIR.
So, we discussed how interface interoperability would work when using Rhapsody in this role. We settled on the fact that Rhapsody would be the fastest and least expensive way to get a solution in place.
The NCHS created a community of practice. We attended monthly meetings with implementers from around the country to discuss how to meet the challenge of integrating death certificates using FHIR.
Several states employ Rhapsody for sending FHIR to and from NCHS because of ease. It’s already in-house, so the time to get an interface in place is quicker. It can integrate with any legacy Electronic Death Registration System (EDRS) and depending on the database, you can adapt them all.
AC: You’ve been on the cutting edge working with CCDA, now you’re implementing FHIR as a key member of the Rhapsody working group, a resource of folks who have tread the path already. Can you share with the audience how they can accomplish what you have?
JD: We have a subgroup of the community of practice Rhapsody working group, for all states that are either working with Rhapsody or interested in working with Rhapsody for this or any other public health use case.
We meet once a month; if someone wants to participate, they can send me an email. The doors are open to all public health Rhapsody Integration Engine implementers to come and learn. We talk about workflows, routes, and testing. We’ve shared test cases so we can help each other solve this problem together.
On its surface, you think sending ICD-10 codes to NCHS or getting codes back is easy. But when you start digging into requirements, you have to put into a production exchange, a production interface… This route accounts for the anticipated scenarios that we talked through in our group.
Technology in healthcare and public health is complicated. It helps when you have a group of peers in other jurisdictions that are doing the same thing because. Ultimately everyone’s route may not look the same, but we can share challenges and ideas.
AC: What were some challenges you faced as an early adopter of FHIR?
JD: The FHIR implementation guide was not fully settled. If you don’t have a solid implementation guide, you don’t have a standard. Changes to the implementation guide change things in the route and in thought processes and tend to snowball. At the big picture level, things are always more complicated than you think they’re going to be.
AC: Every system is their own single source of truth for their particular domain, yet patients live in each different system. How are you solving the patient matching problem?
JD: We have an EMPI tied to the Medicaid data warehouse. In the Michigan DHHS, this data warehouse gets data from most big production systems in the HHS department and maintains an MPI from those systems. It can be a little difficult to get data out of and to use operationally.
What’s intriguing to me is the ability to extract patient matching information as data flows through Rhapsody Integration Engine in or out, and to link them in a cloud based EMPI that could provide timely patient matching. There aren’t tools for us to go in and to assess match quality, resolve near matches, or check for false positive matches.
That’s why we’re looking at capturing data that goes in and goes out of Rhapsody Integration Engine death events during COVID. We manually matched in Michigan; once a week I would get a file from our disease surveillance system and run a manual matching algorithm. I would produce a match and email it back to the surveillance system in a CSV file, which then they would upload. It’s a delay in the process. But public health can’t wait and nor should it have to. Those things can be done in real time as the data flows in and out.
AC: You want to make good use of taxpayer dollars, so it makes sense to try to solve at an enterprise level. But it means multiple stakeholders and common data quality requirements. Rhapsody has our own EMPI solution and we’ve made the integration between the integration engine and our EMPI seamless for those who want to use both in their data flow.
DI: It’s common to make an API call to the EMPI as the data is moving through a Rhapsody Integration Engine route. It’s intended to be used in real time. If there’s not a clear match and a human has to intervene, that goes to a work queue, so it may be asynchronous. But definite matches/non-matches go quite quickly.
DI: What about legal issues with sharing vital records with other programs, like disease surveillance?
JD: Two health departments I’ve worked for have no barriers with inter-departmental sharing. When you get into sharing identifiers with staff for use cases or with external data partners, then yes, there’s going to be challenges. But connecting the dots between a person in an immunization registry or in duplicates in an immunization registry using birth certificate data is standard practice. For matching and linking operational purposes, most states would be permissive for that use within health departments.
DI: How much focus is there on detecting or trying to correct data quality issues?
JD: Depends on the data. Electronic systems do a good job at ensuring that required fields are there for death certificates. But in some cases, they may not know a birthday, age, or identity, or we get an unknown or pending cause of death.
I don’t think we see a lot of missing data because our systems require it to register a death certificate and people need that death certificate to accomplish some business. Sometimes it’s subject to debate and different fields are questionable. There are data quality issues sometimes with things like race and ethnicity, marital status, other check boxes on the death certificate.
DI: Because FHIR is unfamiliar to a lot of customers, does the Rhapsody team have professional training for FHIR?
AC: We offer FHIR courses on our Academy, an online resource for existing customers that’s included with the support and maintenance contract. Professional services are available for contract on a project or hourly basis.
DI: We like to think of Rhapsody Integration Engine as a toolkit of useful functionality for accomplishing integration needs. We have the Rhapsody Integration Engine, the Enterprise Master Patient Index (EMPI), a code management and maintenance solution to promote semantic interoperability… together you can accomplish pretty much anything you need to with your interoperability tasks.
For further reading:


